
How to lead your ML team to success?

You probably read it multiple times already but according to a recent study, 55% of companies never take their models to production. And that’s only if projects are successful - when others predict that 87% of projects fail.
You can blame your data team, but in most cases, unsuccessful ML projects have nothing to do with ML itself, but how you approach it, manage it and integrate it into your product. Managers, board members need to have skin in the game, too.
"AI rewards people who are willing to learn and think differently. Then, it delivers its tremendous potential."
Forget what you learned about software. Leading an ML team to success is something else.
Machine learning is unique because it’s non-deterministic and goes beyond our control. Some key differences between software and ML projects include: Project Feasibility, Knowing it works, Progress Tracking, Task Estimation.
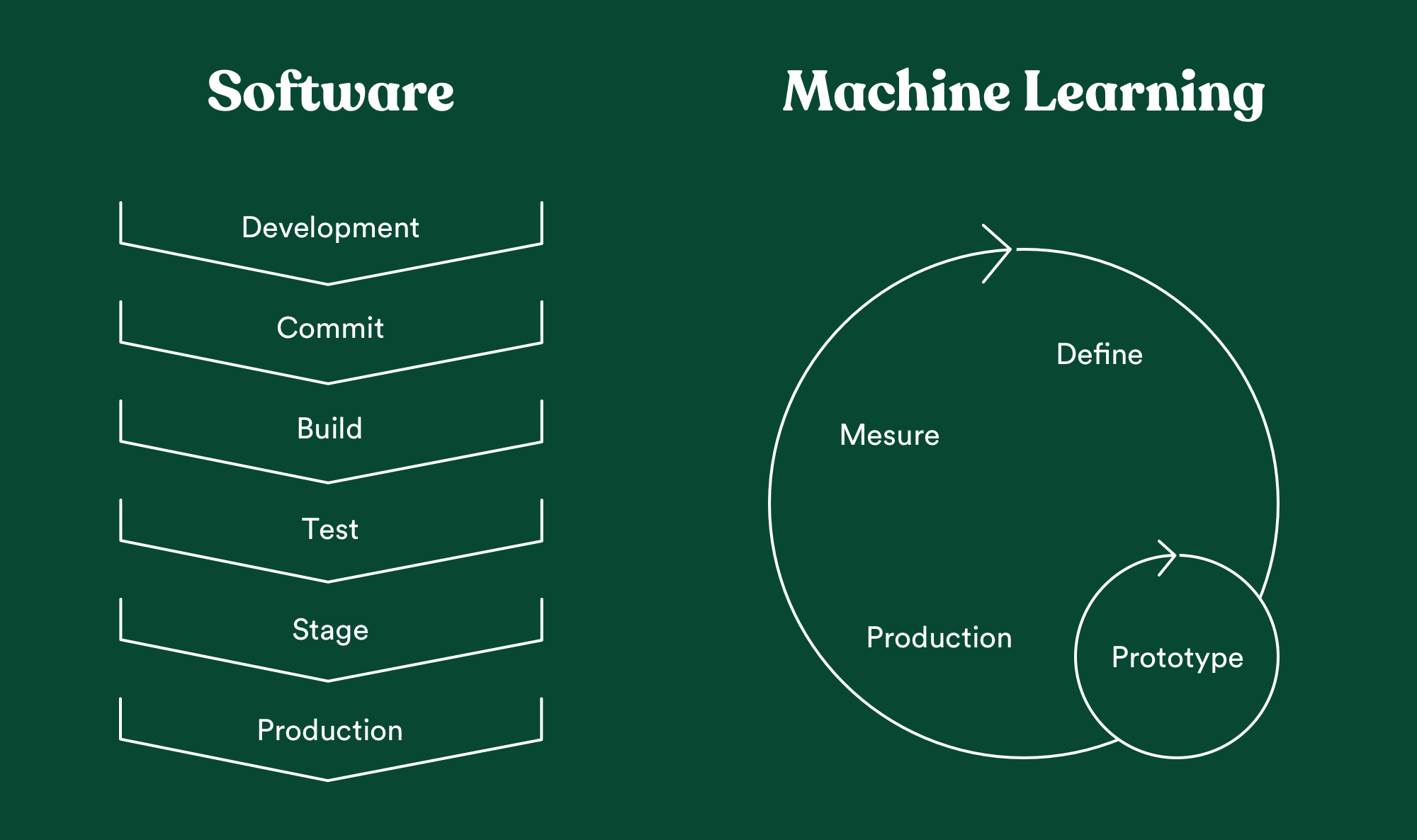
You're definitely not building another dating app, as a data science manager your job is closer to drug discovery: high investment, high uncertainty for possible high outcomes. Or like an entrepreneur, if you prefer.
With ML even when it works, and it performs pretty well from the data science point of view still the outcome is near useless for the business, and the bias it creates along the way can be devastating to the user, and society as a whole. Great power implies great responsibility, amirite? 🥸
As data science continues to mature and become ever more integrated with operationalized systems, the role of the data science product manager is becoming more critical. We still need frameworks and tools to mitigate risks and improve project outcomes at every stage of the life cycle.
This is what it takes to lead an ML team that delivers.
Setup: Prioritize for impact
Good data team hiring won't replace the need for good tooling, according to Dataiku - but even good tooling can't replace prioritizing and estimating a project.
In most cases, data scientists don’t understand the business need for the product, not because they can't, but because the organization may isolate them from the strategy side. By translating the business needs into a language the data scientists can understand and by explaining the “why” behind a product, the product manager focuses the team on value-delivery.
Prioritization seems trivial once a proper assessment is done, and you may assume you can just plot the results and pick the most attractive one. In practice, this is rarely the case for AI use cases.
Here we will use a simple framework that you should already know: complexity versus benefits.
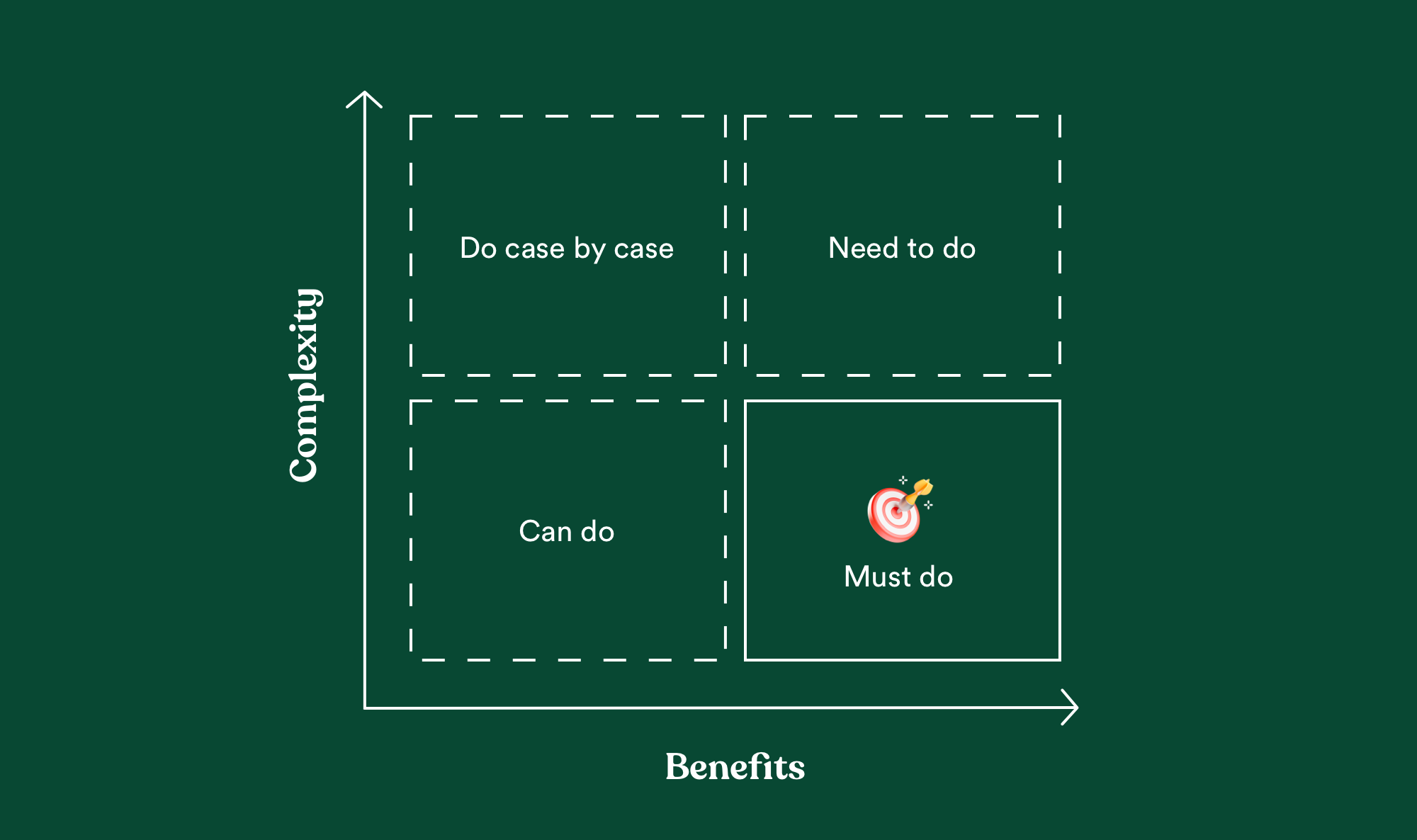
"But you just spent 5 minutes explaining that ML is THAT different" I know, the framework is kind of standard, but what you'll rank in is another world from software.
Starting with the complexity side. As an AI PM, you’ll leave the tech complexity to your DS team. Just a reminder. But still, when you’re planning a product, it’s important to have a gut feel for what error rates are achievable and what isn’t, and what error rates are acceptable for your application. Avoid unachievable error rate use-cases at all costs.
Now on the benefits part, you need to ask yourself several questions to make sure you have enough vision on what you're trying to prioritize from 2 main perspectives.
- First, user experience: Is the upside of this ML product from a UX perspective justify spending way more time and money than a non-ML alternative? If the ML fails, how badly will it impact the UX?
- Then, profit: How about the cost of the data, the research, and the production? Can you roughly put a number on how much value a prediction will create based on every scenario of your confusion matrix? If you're interested in having a better way to link business outcomes from model outputs, we'll cover this topic in detail later on.
Naturally, you'll rank higher the use-cases that maximize value (for the user and the business) and minimize risks on a scale from 1 to 10.
Managers should NOT prioritize according to their gut, quick wins, or the user. Because you're biased, there's no quick win in ML and users don't know what you should build.
Once everything is ranked, go bottom right first: maximum user benefits, minimize tech complexity.
Often, we are distracted by the newest and sexiest AI methods. Refocus your efforts on less complex AI. Why? Because less complex AI methods generally have more predictable outcomes.
Especially if you’re starting in ML, you should aim to build org’s confidence in AI, with "must-do" ideas, before moving on to the more difficult ideas.
Communication: Shared language, expectations, and goals
Since estimating an ML project is near impossible, you remain with two cards to play: making sure to set the goal right with the data team, and set the right expectations with the board.
One of the most powerful tools to align everybody is to create a shared language.
A language that everyone can agree on, something quantifiable and directly connected to your business. If a data scientist just built a model that optimizes one of the standard metrics such as AUC or F1 score, the business would likely be leaving money on the table. In other words: business goals must drive modeling goals.
But it's not a one-way conversation, some ML concepts are important to understand for everybody, especially your stakeholders, we make sure their expectations are not off the chart and build trust for this common ground.
Acceptance criteria
Acceptance criteria are an agreement between product managers and engineers on what exactly a software feature should include. Defining acceptance criteria is a joint effort that can take significant time, but it’s worth the investment. Good acceptance criteria ensure that both sides understand the task in the same way.
Acceptance criteria for data science tasks and machine learning models need to do the same thing. They must translate business requirements to clear modeling metrics.
But how can you set precise acceptance criteria? Knowing that in the ML field, achieving a 90% accuracy rate can cost you months, and adding a few percentages might cost you years, even your lifetime.
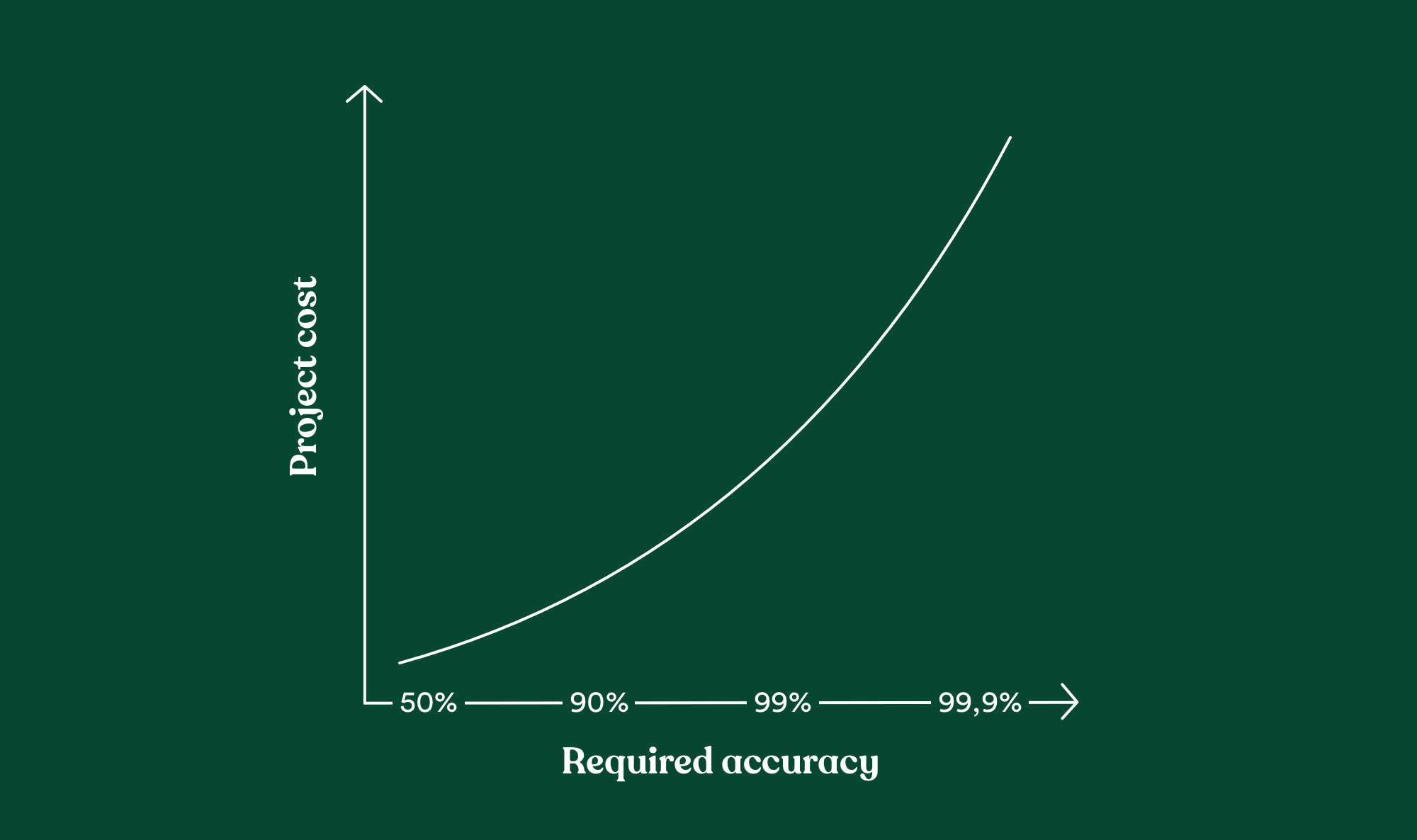
First, work with your team to know which could be a reasonable target, and it should not cost you too much time since you've prioritized not so time-consuming use-cases.
Then, once again it's important to create a bridge between the business and the model performance, so you don't have to approximately guess what would be an acceptable accuracy. And it will be easier for you to link the data team to the business requirements, and communicate results to stakeholders.
Recalling the fact that ML project costs tend to scale super linearly: It is critical to put the model into an ROI perspective early on because you definitely don't want to invest time and effort on a model that won't produce the desired outcome for your business at the end of the first iteration.
Set stakeholder expectations
« What’s the AI team up to? »
This is what you'll most likely hear from your stakeholders.
The black box effect isn't limited to your models, it applies to your project too.
Getting data and building, deploying, and maintaining models is a considerable investment. The risk is omnipresent and the outcome can be astronomical. In a sense, it reminds me of a founder-investor relationship.
And as the founder of the AI team, you need to be in control of what you can deliver. If you don’t set expectations, some else will. The measure of success of a product will be defined by their expectation.
Many businesses tend to justify the costs of ML products that require large research investments by setting high expectations for what can be achieved by ML. As a PM, you should align expectation to reality and set the following expectations:
- AI & data product often fail to make it to launch
- The error rate is not certain!
- Investing in AI does not always result in a successful model
- Common is failure
2. AI is not magic
- Set the expectation, they are science
- Not all problems can be solved with AI
3. AI takes time
- Trial and error development -> Long term thinking and investment
Also, educate your org on how AI modeling works. And provide frequent updates of each stage of product development.
Even with a healthy relationship base, you need to maintain it through the lifecycle of the project. Especially when the time of sharing results has to come. Let's face it: stakeholders don’t know how to use the results.
The nuances of model interpretation are often not understood by the customer, and data scientists might not be able to effectively set expectations or explain why the most “accurate” model might not be the best.
Sure, A product manager who understands data science could better facilitate communication among the data scientists and stakeholders. But not everyone is willing to learn how to read a ROC curve or the difference between precision and recall.
Sometimes less is more. When representing results to stakeholders, I can't recommend enough to balance data metrics with business metrics—your shared language—giving them keys to interpret your team's results, and the correlation between the model outputs with the business outcomes.
Test: Evaluating performance
Data science is, by design, a deeply data-driven team. Evaluation happens at every iteration of the ML journey.
Based on the evaluation results, your team can choose the best model, optimize the model's parameters while training or even after the deployment in production.
Before mastering every evaluation metric, you should be comfortable with the fruit of the evaluation. I call it "Owning the confusion matrix".
Once your model is being evaluated on a specific dataset, the predictions fall into four groups based on the actual known answer and the predicted answer. The below representation of actual and predicted values is termed as Confusion Matrix.
- Correct positive predictions — True positives
- Correct negative predictions — True negatives
- Incorrect positive predictions — False positives
- Incorrect negative predictions — False negatives
Typical metrics for classification problems are Accuracy, Precision, Recall, False positive rate, F1-measure, and these are derived from Confusion Matrix.
From a Data Scientist perspective, each metric measures a different aspect of the predictive model but you can derive a lot of insights from a confusion matrix based on your use case. But, they may feel a little bit disconnected from the user desirability and the business viability of your ML product.
Give real-life meaning to the confusion matrix by translating every group into cost and profit centers, and having empathy by translating the same groups for the emotion of the end-user: those who will face your prediction on their input. It will give you:
- An exhaustive vision of your model impact, both on the UX and business.
- Keys to design a graceful error recovery
- Insights to arbitrate which evaluation metrics you should optimize for since precision emphasis more on false-positive and recall on false-negative, for exemple.
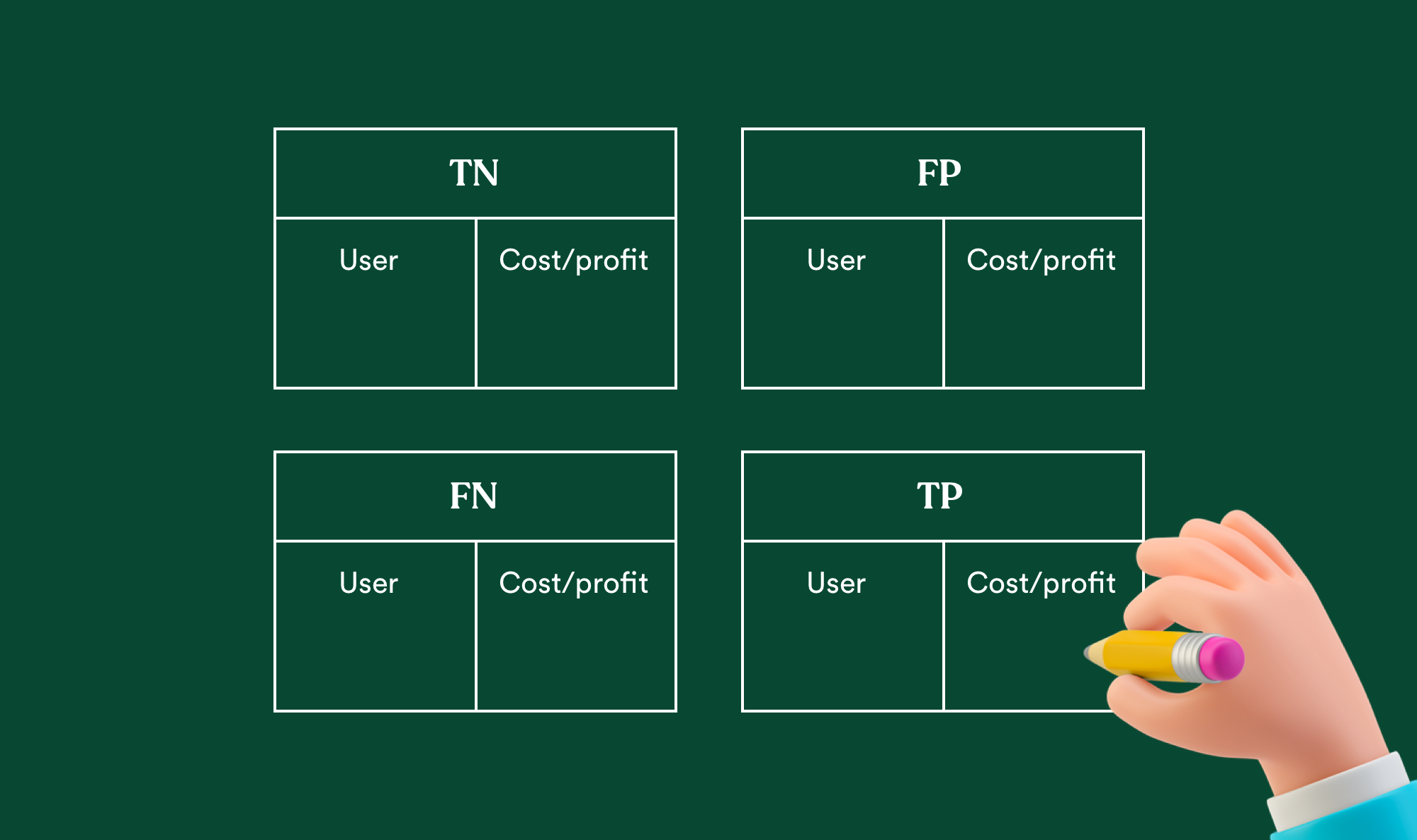
Every use case is unique in terms of how the user will react when the model fails to perform a correct prediction. Performing a bad movie recommendation is not that critical compared to predicting the wrong disease and treatment. And you can imagine the same goes for viability.
Pro-tip: You can also bridge those metrics with product metrics for more correlation!
It's also critical to project those metrics into a timeframe to make sure you're not hitting a plateau yet and to anticipate diminishing returns.
If you struggle on this step, stick with us, we may share with you our secret sauce, and by sauce I mean tool :)
You got it right: Linking business to data science is the more critical aspect to achieve success in AI/ML.
At every stage of the life cycle, you will ensure you're on the path of success if you can bridge those two worlds.
It's not about how to micro-manage a team, it's about building common ground, a shared language, a culture where everyone is on board and understands each other effortlessly.
Then, the conversation isn't around unachievable timeframes, use-cases, and results, but on an achievable value that the AI team can deliver, quantified in a readable way: dollars.
Congratulations! You've reach the end of this blog post. As a reward, here's my secret sauce. Introducing ✨guap✨
guap is an open-source python package that helps data team to get an ML evaluation metrics everyone can agree on by converting your model output to business profit. It's entirely free, give it a try!
 guap-ml
guap-mlAlso if you want more advanced insights, we've put together a free 7 days "AI product metrics: Outputs to outcomes. Prediction to profit." email course that will give you all the keys to set up your next AI product with in-depth methodology, examples and our canvas included! Interested? Subscribe here and receive the first part immediately.
That's it for now. Now your turn: how do you track your AI investments and estimate the profitability of your model?